YaRN: RoPEベースLLMの長文脈拡張手法
1. はじめに:YaRNはどのような課題を解決する技術なのか?
1.1 背景と直面している問題点
max_position)を伸ばしたり、学習時に経験していない長さのデータをそのまま入力(外挿)したりすると、離れたトークン同士のAttentionが不安定になり、精度が大きく崩れてしまうことが知られています [1][2][3]。
1.2 YaRNの核となるアイデア
- 低周波帯(波長が長い): 学習時の文脈長の中では1周(1サイクル)しきらないことも多く、本来は「相対的な位置」を表すはずが、実質的に「絶対的な位置」の目印として使われることがあります。
- 高周波帯(波長が短い): すぐ近くにあるトークン同士の順番や、局所的な距離感を区別するのに役立っています。
1.3 適用できるモデルと前提条件
1.4 本記事の構成
2. RoPEの特性と長文脈への外挿が破綻するメカニズム
2.1 記号の定義と前提知識
2.2 RoPEの基本的な性質
2.3 周波数帯ごとの役割の違い
- 高周波帯: 短い距離でも位相(角度)が大きく変わるため、近くにあるトークン同士の順序や、局所的な位置関係を識別するのに役立ちます。
- 低周波帯: 学習時の文脈長 \(L_{\text{train}}\) の範囲内では1周すらしないような長い波長成分は、学習データの中では位置ごとにほぼ一意の位相を持っています。そのため、理論上は相対位置を表現するものであっても、実際には「絶対位置に近い目印(アンカー)」として機能してしまうことがあります。
2.4 長文脈への外挿が失敗(OOD)する理由
- 未知の相対距離(第一のOOD): 学習範囲を超えるような遠距離の位相差に対しては、Attentionの重みが最適化されていません。
- 絶対位置アンカーの崩壊(第二のOOD): 低周波帯が学習時に「準・絶対位置」として機能していた場合、系列が長くなるとその前提が崩れます。学習時は特定の場所を指し示していた位相構造が、長い系列ではまったく別の位置関係を意味するようになってしまうからです。
2.5 一様に補間すると局所的な解像度が落ちてしまう理由
3. 長文脈適応手法の進化
3.1 単純外挿の限界
3.2 Position Interpolation(PI)によるブレイクスルー
3.3 NTK-aware の登場とその課題
3.4 帯域別設計へのパラダイムシフト(YaRNへ)
4. 帯域ごとの補間と attention logit の再調整
4.1 NTK-by-parts:周波数帯ごとの補間設計
4.2 なぜ低周波と高周波を分けるのか?
4.3 attention logit 全体の再調整(スケーリング)
4.4 YaRN の全体像まとめ
- 帯域別のRoPE変形: 低周波帯は強く補間し、高周波帯はできる限り維持する。
- グローバルなスケーリング: 変形によって生じる attention logit のズレを再調整する。
4.5 実装の手軽さというメリット
5. 推論時の拡張:スケール手法の選択と実装上の壁
5.1 固定スケールと動的スケール(Dynamic Scaling)の違い
5.2 なぜDynamic Scalingが有利なのか
- 短い文脈を入力した際の性能低下(回帰)を防ぎやすい
- テキストが長くなっても、性能の劣化がゆるやかになる
- 学習時に想定していなかった中途半端な長さに対しても柔軟に対応できる
5.3 KVキャッシュと実装面でのハードル
5.4 実運用(サービング)における注意点まとめ
6. 事後学習の戦略とモデルの評価方法
6.1 長文そのままのファインチューニングが非効率な理由
6.2 YaRN の優れた収束特性
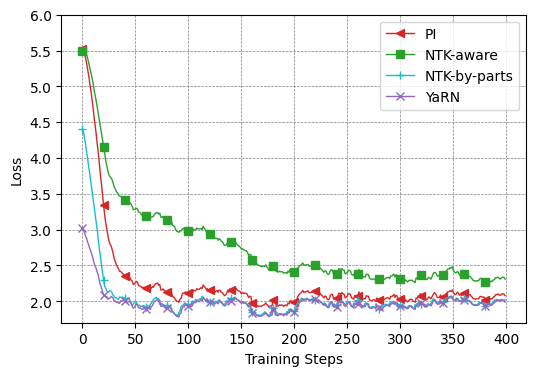
図: LLaMA 7B を 32k 文脈へ拡張したときの training loss curves (YaRN 論文の Figure 2 より引用)
6.3 段階的なコンテキスト拡張のすすめ
7. YaRNと他手法との比較
7.1 評価のポイント
7.2 RoPE系手法との比較
7.3 非RoPE系手法との比較
7.4 YaRNを採用すべき条件
- ベースとなるLLMがすでにRoPEを採用していること。
- モデルのアーキテクチャ自体には大きな変更を加えたくないこと。
- フルスクラッチでの再学習ではなく、比較的コストの低い継続学習(fine-tuning)で対応したいこと。
- FlashAttentionなどの既存の推論・サービング環境との互換性を保ちたいこと。
7.5 注意点と限界
- どんなに設計を工夫しても、元の短い文脈における性能低下(劣化)を完全にゼロにすることはできません。
- 文脈長に応じて倍率を変えるDynamic Scalingを採用する場合、KVキャッシュの管理など推論システム側の実装条件が厳しくなります。
- 当然ですが、RoPE以外の位置表現を使っているモデルには適用できません。
- 言語モデルの長文脈への対応力は位置表現だけで決まるわけではなく、学習データの分布やタスクの特性によっては、別の根本的なアプローチが必要になる場合もあります。
8. まとめ
9. 参考文献
- Bowen Peng, Jeffrey Quesnelle, Honglu Fan, Enrico Shippole, et al. YaRN: Efficient Context Window Extension of Large Language Models. arXiv:2309.00071
- Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
- Shouyuan Chen, Sherman Wong, Liangjian Chen, Yuandong Tian. Extending Context Window of Large Language Models via Position Interpolation. arXiv:2306.15595
- Ofir Press, Noah A. Smith, Mike Lewis. Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. arXiv:2108.12409
- Yutao Sun, Li Dong, Barun Patra, et al. A Length-Extrapolatable Transformer. arXiv:2212.10554
- Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. Attention Is All You Need. arXiv:1706.03762
- Peter Shaw, Jakob Uszkoreit, Ashish Vaswani. Self-Attention with Relative Position Representations. arXiv:1803.02155
- Colin Raffel, Noam Shazeer, Adam Roberts, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683
- Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, Siva Reddy. The Impact of Positional Encoding on Length Generalization in Transformers. arXiv:2305.19466
最終更新日: 2026年4月5日