* This document is a note that I researched and organized with the help of ChatGPT/Gemini in order to organize my own understanding.
YaRN: A long-context extension method for RoPE-based LLMs
1. Introduction: What problem does YaRN solve?
1.1 Background and the problem being faced
How long a piece of text a large language model (LLM) can handle at once (its context length) is not determined solely by the model's blueprint. In practice, it is strongly influenced by "how token positions were represented" during pre-training, and by how attention was trained to behave within that range.
Today, many decoder-type LLMs, starting with LLaMA, widely adopt a position representation called RoPE (Rotary Position Embedding). However, it is known that if you simply extend the configured maximum length (max_position) of a model that uses RoPE, or feed in lengths it never experienced during training (extrapolation), the attention between distant tokens becomes unstable and accuracy collapses significantly [1][2][3].
The root of this problem is not something as simple as "the model has never seen long text." The cause is that "the balance (geometry) of the position space that the trained model assumed changes abruptly at inference time." In other words, long-context extension is not a matter of "simply increasing the number of input characters while preserving the existing model's abilities." It must be understood as a delicate design problem: "how can we stretch out the positional structure that the trained attention heads rely on, without breaking it?"
1.2 The core idea of YaRN
YaRN's approach starts from the realization that "not all frequency bands that make up RoPE play the same role" [1].
RoPE contains various frequency bands depending on wavelength.
- Low-frequency bands (long wavelength): Within the training context length they often do not complete even one full cycle, so although they are supposed to represent "relative position," they can effectively be used as markers of "absolute position."
- High-frequency bands (short wavelength): They help distinguish the ordering of nearby tokens and the local sense of distance.
If the roles are divided in this way, it is not reasonable to stretch all frequency bands uniformly when extending the context. YaRN therefore adopts a band-by-band design with clear contrast: "strongly interpolate (shrink) the low-frequency bands so they do not fly outside the training range, while keeping the high-frequency bands as close to their original state as possible." Furthermore, it cleanly corrects the resulting shift in the attention logits (the distribution of scores) with an overall scaling.
In one sentence, YaRN can be described as "a method that carefully adjusts RoPE's frequency balance band by band, and then re-tunes how strongly attention acts on top of that" [1].
1.3 Applicable models and prerequisites
What YaRN assumes is "a decoder-type LLM that has already been pre-trained using RoPE." For this reason, it shows its true value when you want to easily extend the context of an existing RoPE model, rather than for a brand-new model whose position representation can be designed from scratch.
In particular, it pairs very well with needs such as "I do not want to significantly change the fundamental structure of the model or the inference environment (the serving system)" and "I want to handle it smartly through continued pre-training or fine-tuning" [1].
Conversely, YaRN is not a magic wand that can be directly applied to models using position representations other than RoPE. Also, note that whether a model can handle long text well is not determined by the position-representation method alone; the quality of the training data, the training curriculum, the evaluation method, and so on also matter [1][9].
1.4 Structure of this article
In this article, we first unravel the inherent properties of RoPE and the mechanism by which simply extending it to long contexts breaks down.
Next, we organize the evolutionary flow from simple extrapolation through "Position Interpolation (PI)" and "NTK-aware" up to YaRN, and explain in detail the heart of YaRN: "band-by-band interpolation" and "re-tuning of the attention logits."
After that, we touch on the mechanism of Dynamic Scaling at actual inference time, how to proceed with post-training, and evaluation metrics. Finally, through comparison with other methods, we summarize "in which cases YaRN should be chosen."
2. The properties of RoPE and the mechanism by which extrapolation to long contexts breaks down
2.1 Notation and prerequisites
In this article, let the maximum context length at pre-training time be \(L_{\text{train}}\) and the target maximum context length after extension be \(L_{\text{target}}\), and define their ratio (scale) as follows.
\[
s = \frac{L_{\text{target}}}{L_{\text{train}}} > 1
\]
Let the attention head dimension be an even number \(d_h\), and index each 2-dimensional pair by \(j = 0, 1, \dots, d_h/2 - 1\). The rotation matrix in RoPE is given as follows.
\[
R(\phi) =
\begin{pmatrix}
\cos \phi & -\sin \phi \\
\sin \phi & \cos \phi
\end{pmatrix}
\]
The application of RoPE to the \(j\)-th 2-dimensional component \(x^{(j)}\) of an input vector \(x\) is defined by the following equation.
\[
\operatorname{RoPE}(x,m)^{(j)} = R(m\theta_j)x^{(j)}, \qquad \theta_j = b^{-2j/d_h}, \; b = 10000
\]
Here, \(m\) denotes the token position. In the explanation that follows, we make use of the fact that "shrinking the position" and "shrinking the frequency" are mathematically equivalent.
\[
e^{i(m/s)\theta_j} = e^{im(\theta_j/s)}
\]
That is, an approach to long-context extension is the same whether you think of it as "interpolating position \(m\) to \(m/s\)" or as "designing a new effective angular frequency \(\tilde\theta_j\)." In this article we proceed with the latter viewpoint.
2.2 Basic properties of RoPE
The greatest feature of RoPE is that, rather than simply adding position information to the embedding vector, it rotates the Query and Key spaces themselves. The rotation matrix has the following property.
\[
R(m\theta_j)^\top R(n\theta_j) = R((n-m)\theta_j)
\]
Because of this, when you compute the inner product of a Query at position \(m\) and a Key at position \(n\), you get the following.
\[
\langle \operatorname{RoPE}(q,m), \operatorname{RoPE}(k,n) \rangle = \sum_j (q^{(j)})^\top R((n-m)\theta_j)k^{(j)}
\]
As this equation shows, RoPE is designed so that in computing the inner product it depends not on the absolute position itself but on the relative distance \(n-m\). This is a major reason why RoPE is adopted in many decoder-type models.
2.3 The difference in roles across frequency bands
The wavelength corresponding to the angular frequency \(\theta_j\) of each dimension is computed as follows.
\[
\lambda_j = \frac{2\pi}{\theta_j} = 2\pi b^{2j/d_h}
\]
The smaller \(j\) is, the shorter the wavelength (high-frequency band); the larger \(j\) is, the longer the wavelength (low-frequency band). By combining multiple frequency bands in this way, RoPE represents position with precision.
An important point here is that, in the actual training process, "not all bands are used in the same way."
- High-frequency bands: Because the phase (angle) changes greatly even over short distances, they help distinguish the ordering of nearby tokens and local positional relationships.
- Low-frequency bands: Long-wavelength components that do not complete even one cycle within the training context length \(L_{\text{train}}\) have an almost unique phase at each position within the training data. Therefore, even though they theoretically represent relative position, in practice they can end up functioning as "markers close to absolute position (anchors)."
2.4 Why extrapolation to long contexts fails (OOD)
Because RoPE is based on relative distance, at first glance it seems it could naturally adapt to (generalize over) long sequences. In reality, however, it does not go so well.
The root of the problem is that what the model experiences during training is limited to the range from \(0\) to \(L_{\text{train}}\).
- Unknown relative distances (the first OOD): Attention weights are not optimized for phase differences at long distances beyond the training range.
- Collapse of the absolute-position anchor (the second OOD): If the low-frequency bands functioned as "quasi-absolute positions" during training, that premise breaks down as sequences grow longer. This is because the phase structure that pointed to a specific location during training comes to mean an entirely different positional relationship for long sequences.
In this way, extrapolation to long contexts produces a double out-of-distribution (OOD) state. The statement in the Position Interpolation (PI) paper that "interpolating positions is theoretically far more stable than simple extrapolation" reflects exactly this situation. Whether the relative-position equation is preserved and whether the trained model can withstand that change in phase are entirely separate matters.
2.5 Why uniform interpolation degrades local resolution
So, to avoid OOD at long distances, would it be enough to shrink all frequency bands by the same ratio (uniformly)? In fact, this is not the optimal solution either.
In the original RoPE, the phase difference between adjacent tokens is as follows for each band.
\[
\Delta \phi_j = \theta_j
\]
However, if you interpolate uniformly, you get the following.
\[
\Delta \phi_j^{\text{(uniform)}} = \frac{\theta_j}{s}
\]
In this way, the phase difference becomes smaller (compressed) in every band. High-frequency bands originally play the role of finely distinguishing local ordering, but if you compress them uniformly, you also lose the resolution at short distances.
Therefore, the approach truly needed for long-context extension is to "interpolate the low-frequency bands while avoiding extrapolation outside the training range, and preserve the high-frequency bands as much as possible to maintain local discriminability." Building this point clearly into its design is the innovative part of the YaRN method.
3. The evolution of long-context adaptation methods
3.1 The limits of simple extrapolation
The simplest and most easily conceived approach is to extend the range of position IDs used in pre-training as-is and apply the same RoPE to longer positions as well. However, this method has limits. Because "large phase differences" that the model never experienced during training are suddenly fed in, the attention scores at long distances tend to become unstable.
Mathematically, RoPE looks as if it handles relative positional relationships well. In reality, however, the essential reason extrapolation breaks down is that the trained weights are merely overfitted (optimized) to a phase geometry composed of "finite lengths."
3.2 The breakthrough of Position Interpolation (PI)
The first to present a clear solution to this extrapolation problem was "Position Interpolation (PI)."
PI's idea is very intuitive: rather than forcibly extrapolating a longer sequence, it "squeezes it (interpolates) into" the original trained position range. From the frequency viewpoint, PI has the same effect as applying the following equation to all bands.
\[
\tilde\theta_j^{\text{(PI)}} = \frac{\theta_j}{s}
\]
Stated from the position viewpoint, this can also be rephrased as computing RoPE after compressing the original position \(m\) to \(m/s\).
The biggest benefit of PI is that it can avoid recklessly flying out into regions unknown to the model (raw extrapolation). This makes it possible to smoothly adapt to long contexts with relatively little additional continued training. Indeed, the PI paper demonstrates that it reaches the target context length far faster than directly fine-tuning by simply feeding in long sequences.
3.3 The advent of NTK-aware and its challenges
PI is excellent, but it also had a weakness: it "compresses all frequency bands by a uniform ratio." As a result, it also strips away the resolution of the "local information in the high-frequency bands" used for tasks such as grasping the ordering of nearby tokens.
What emerged from the community in an attempt to compensate for this drawback is the family of methods called "NTK-aware." The basic concept of NTK-aware is to maintain the ability to discriminate local relative positions by "leaving the high-frequency bands as close to the original as possible and strongly shrinking only the low-frequency bands."
The direction is very reasonable, but NTK-aware had a practical bottleneck: you have to explore how much to change the effective base by heuristics, and it is hard to control directly relative to the target extension factor. In other words, although the idea is good, it was still insufficient as a design principle.
3.4 A paradigm shift toward band-by-band design (toward YaRN)
Through this evolutionary process, the focus shifts toward the essential understanding that "the roles differ across RoPE's frequency bands."
Low-frequency bands tend to work as "quasi-absolute positional anchors" within the training range, while high-frequency bands contribute to grasping "local relative ordering." If we correctly account for this difference in roles, the most natural approach is to explicitly design "which bands to interpolate, and by how much" when extending the context.
YaRN is a method that places exactly this "band-by-band design" at its core. It inherits the training stability of PI while incorporating the idea of preserving the high-frequency bands that NTK-aware aimed for. Furthermore, by re-tuning the whole—including the attention scale—it tries to solve long-context adaptation more systematically and more powerfully.
4. Band-by-band interpolation and re-tuning of the attention logits
4.1 NTK-by-parts: interpolation design for each frequency band
At the core of YaRN is the band-by-band RoPE transformation approach called "NTK-by-parts" in the paper.
First, we compute how much each frequency band rotated within the training context length, using the following equation.
\[
r_j = \frac{L_{\text{train}}}{\lambda_j}
\]
This \(r_j\) is a rough measure of how many cycles that dimension completed within the training range. Next, using two thresholds \(\alpha\) and \(\beta\), we define a linear ramp function \(\gamma(r)\).
\[
\gamma(r)=
\begin{cases}
0 & (r < \alpha) \\
1 & (r > \beta) \\
\frac{r-\alpha}{\beta-\alpha} & (\alpha \le r \le \beta)
\end{cases}
\]
Using this, we determine the effective angular frequency after extension as follows.
\[
\tilde\theta_j^{\text{(NTK-parts)}} = \left(\frac{1-\gamma(r_j)}{s}+\gamma(r_j)\right)\theta_j
\]
The equation may feel a little complex, but what it means is very simple. In the "long-wavelength (low-frequency) bands" where \(r_j\) is small, \(\gamma(r_j)\) approaches 0, so it is strongly interpolated toward \(\theta_j/s\), just like Position Interpolation (PI). Conversely, in the "short-wavelength (high-frequency) bands" where \(r_j\) is large, \(\gamma(r_j)\) approaches 1, so the original frequency is preserved as-is. And in the intermediate bands, the mechanism interpolates smoothly to connect the two.
4.2 Why separate low and high frequencies?
The aim of separating the bands in this way is to "suppress the long-distance unknown-data (OOD) problem that occurs in the low-frequency bands, while retaining as much as possible the local positional discriminability of the high-frequency bands."
In conventional PI, all bands were shrunk uniformly to avoid extrapolation to unknown distances, but the resulting weakness was that even the fine resolution of the high-frequency bands was lost. NTK-by-parts minimizes this cost.
In other words, rather than simply stretching RoPE overall, YaRN takes the clever approach of identifying "which bands are weak against unknown lengths" and applying strong interpolation only where necessary. A major feature of this method is that it does not lump the frequency structure together but processes each band with its meaning separated.
4.3 Re-tuning the entire attention logit (scaling)
What decisively distinguishes YaRN from PI and NTK-by-parts is that it not only changes RoPE's frequencies but also re-tunes the scale of the attention logits.
Ordinary attention is computed as follows.
\[
\operatorname{softmax}\left(\frac{q_m^\top k_n}{\sqrt{d_h}}\right)
\]
In YaRN, however, a temperature parameter \(t\) is incorporated here.
\[
\operatorname{softmax}\left(\frac{q_m^\top k_n}{t\sqrt{d_h}}\right)
\]
As an actual implementation, by multiplying both \(q\) and \(k\) after applying RoPE by a coefficient \(c(s)\), it achieves the same effect as multiplying the entire logit by \(1/t\). For LLaMA and Llama 2, the following empirical equation is recommended.
\[
c(s) = \sqrt{\frac{1}{t}} = 0.1\ln s + 1
\]
The purpose of this operation is to calibrate (re-tune), using a single scalar value, the attention distribution that shifted as a result of tampering with the frequencies. Band-by-band interpolation alone does not necessarily match exactly the logit behavior that the trained model assumed. So by adjusting the overall scale, it further reduces the impact on the model.
4.4 Summary of the overall picture of YaRN
Putting everything together so far, we can see that YaRN is not a single-shot technique but a method that combines the following two elements.
- Band-by-band RoPE transformation: strongly interpolate the low-frequency bands and preserve the high-frequency bands as much as possible.
- Global scaling: re-tune the shift in the attention logits caused by the transformation.
With this combination, you can avoid extrapolation to unknown lengths as PI does, preserve the resolution of the high-frequency bands, and bring how strongly attention acts closer to the original trained state. As a result, adaptation to long contexts becomes smooth, and the behavior tends to remain stable even when extending the context length substantially.
4.5 The benefit of easy implementation
What is pleasing from an engineer's perspective is that the changes needed to introduce YaRN are very small.
What you actually need to do is just two things: "change the RoPE frequency computation on a band-by-band basis" and "multiply \(q\) and \(k\) (or the logit) by a scalar coefficient." There is no need to rewrite the attention kernel itself. The reason the paper touts consistency with FlashAttention 2 is precisely this.
You can extend the context of a RoPE model already in operation at a realistic cost, without major surgery on the core of the architecture or the inference server. This is the greatest practical strength that YaRN has.
5. Extension at inference time: choosing a scaling method and implementation walls
5.1 The difference between fixed scaling and Dynamic Scaling
When you actually perform inference using YaRN, there are broadly two approaches to how you handle the extension factor \(s\). One is "fixed scaling," which always applies a constant factor, and the other is "Dynamic Scaling," which varies the factor according to the length of the text (sequence) currently being processed.
In the case of fixed scaling, the following factor is used consistently from the beginning to the end of inference.
\[
s = \frac{L_{\text{target}}}{L_{\text{train}}}
\]
On the other hand, in Dynamic Scaling, letting the current sequence length be \(l'\), the scale is computed as follows.
\[
s(l') = \max\left(1, \frac{l'}{L_{\text{train}}}\right)
\]
That is, the mechanism gradually strengthens the degree of interpolation in proportion to the input text growing longer.
5.2 Why Dynamic Scaling is advantageous
Fixed scaling has the weakness of "applying the final maximum-factor interpolation even while the text is still short." It applies unnecessary transformation even to short contexts, which should originally be able to preserve the geometric structure of the original RoPE as-is.
Dynamic Scaling nicely avoids this problem. It keeps RoPE's original behavior until it reaches the original training length \(L_{\text{train}}\), and only when it becomes necessary beyond that does it smoothly transition to a form suited for long contexts.
This mechanism produces many benefits, such as the following.
- It is easier to prevent the performance drop (regression) when a short context is input.
- Even as text grows longer, the degradation in performance becomes gradual.
- It can flexibly handle in-between lengths that were not anticipated during training.
In the actual YaRN paper's data as well, Dynamic-YaRN shows better performance than the comparison target, Dynamic-PI.
5.3 The KV cache and implementation-side hurdles
Dynamic Scaling is very attractive, but there are non-negligible implementation hurdles when actually building it into a system.
Normally, in the process of text generation (decoding), a KV cache is used to make computation efficient. If you save the "Key after applying RoPE" directly in the cache here, a major problem arises. The moment the text grows longer and the value of the scale \(s\) changes midway, the past Keys saved up to that point no longer mesh at all with the new scale. This is because the RoPE angles must be recomputed with the new scale for all tokens, including past ones.
Therefore, to make Dynamic Scaling work correctly, you need to devise the system's design. Specifically, it requires either holding "the state before applying RoPE" and applying it again later, or a special cache design that can recompute RoPE at any time. Compared with fixed scaling, the demands on the actual operational (serving) environment become considerably stricter.
5.4 Summary of caveats in production (serving)
When operating in an actual production environment, be sure to confirm that "the scale rule assumed at model training time" and "the implementation in production" match well. For example, if you train a model with fixed scaling but run it with Dynamic Scaling only in production, or vice versa, the meaning of RoPE shifts between evaluation time and production, and the model cannot deliver its intended performance.
Also, extra care is needed in environments that use Prefix Caching (caching the common part of prompts), which has become common recently, or that reuse the cache across multiple requests. This is because if the scale value differs per request, cache compatibility is lost.
In summary, when designing an inference environment, you cannot decide based only on "which scaling method is theoretically superior." You need to judge by comprehensively considering all implementation conditions, such as the KV cache specification, compatibility with optimized fused kernels, the cache-reuse strategy, and the various text lengths mixed within a batch. YaRN itself is an excellent method that is easy to introduce into existing models, but if you adopt Dynamic Scaling, you must properly face these system-side constraints.
6. Post-training strategy and how to evaluate the model
6.1 Why fine-tuning on long text as-is is inefficient
You might think that if you simply load long text data and fine-tune (direct fine-tuning), the model will eventually get used to long contexts. However, as pointed out in the Position Interpolation (PI) paper as well, this approach is very inefficient in terms of training and is known to take time to adapt.
The biggest reason is not that the model lacks "knowledge" of long text, but that the "geometric structure of the position space" that the trained model assumed suddenly changes. Because existing attention heads divide their roles based on the phase structure they became familiar with during pre-training, having that premise abruptly broken puts them in a state close to relearning from scratch. What matters most in long-context adaptation is not cramming in new knowledge but "re-tuning the existing attention heads to the new coordinate system with as little burden as possible." What makes PI and YaRN excellent is that they can minimize the distribution shift during this re-tuning.
6.2 YaRN's excellent convergence characteristics
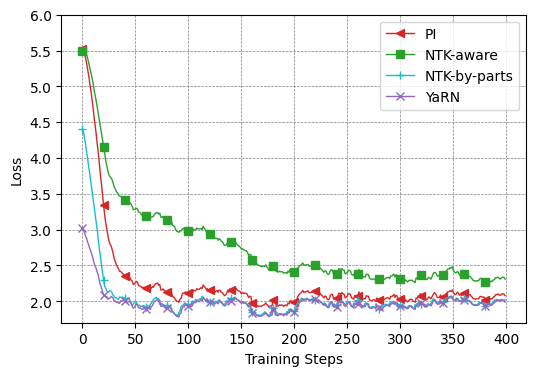
So, how smooth is YaRN's training in practice? The YaRN paper compares the learning curves for extending LLaMA 7B to a 32k context, and at least in this experimental setup, it shows that YaRN's loss drops at an earlier stage than PI, NTK-aware, and NTK-by-parts, and stays low afterward.
This makes a lot of sense given YaRN's design. In the low-frequency bands it prevents extrapolation into unknown regions (OOD) like PI, in the high-frequency bands it maintains the ability of the existing local attention heads, and it further adjusts the logit scale. In other words, YaRN's strength comes down to "not making the model relearn everything from scratch." By greatly changing only the bands that need correcting and leaving the usable bands as-is, it keeps down the cost of additional training and speeds up convergence.
In addition, Appendix B.2 of the paper shows that, in a comparison extending Llama 2 7B from 4k to 8k, YaRN exhibits nearly equivalent perplexity even in fewer, 400 steps, compared with PI, reinforcing the practical advantage that "it tends to reach sufficient performance with little additional training."
6.3 A recommendation for gradual context extension
Also, you do not need to extend all at once to the target context length. The YaRN paper shows that an approach of proceeding with long-context extension gradually is effective.
For example, the image is to first build a 16k long-context model, and using that checkpoint as a foothold, step up to 32k, 64k, and then 128k. By stretching the context length little by little in this way, you can soften the change in data distribution that occurs at once and make training more stable. This strategy is also very convenient in practice. Even when you cannot prepare enough high-quality training data for ultra-long text, you may be able to build a practical long-context model by first stabilizing the model with the data you can obtain, and then combining inference-time extension features with a small amount of additional training.
7. Comparison of YaRN with other methods
7.1 Points for evaluation
When evaluating YaRN, it does not mean much to look only at spec-side aspects such as "how long a context you can achieve." In practice, viewpoints such as "how easily it can be built into an existing RoPE model," "how much additional training cost it incurs," "whether it can maintain the resolution of local positional relationships," and "whether it adversely affects the implementation of the inference server" are important.
Against these criteria, YaRN's greatest strength is that it achieves both "good compatibility with existing models" and "stability when extending at high factors." On the other hand, for a brand-new pre-training project that designs the position representation from scratch, the field of evaluation shifts a little.
7.2 Comparison with RoPE-family methods
First, let us compare with other extension methods based on RoPE.
The simplest is "simple extrapolation," which applies the same position representation as during training directly to long sequences, but because it faces unknown phase differences outside the training range, the attention mechanism tends to break down at long distances.
"Position Interpolation (PI)" was proposed to prevent this breakdown. Because PI compresses (interpolates) the whole down to the size of the training range, it behaves stably, but since it shrinks all frequency bands uniformly, it also sacrifices the "fine resolution of nearby tokens" that the high-frequency bands were responsible for.
Then, "NTK-aware" appeared as an approach that tries to preserve the high-frequency bands as much as possible. Its direction is very close to YaRN, but its design relies on heuristics, and it had the weakness of being hard to control the parameters directly to match the desired extension factor. YaRN clearly formalizes this band-by-band interpolation as "NTK-by-parts," and by also incorporating temperature adjustment of the attention logit, it achieves a more intuitive and controllable design.
Note that there are also methods conscious of length extrapolation, such as XPos and LeX, but because these mainly assume new (from-scratch) training of the model, their use is a little different from YaRN's purpose of "extending a model already trained with RoPE after the fact."
7.3 Comparison with non-RoPE-family methods
For position representations other than RoPE, there are various excellent methods, including absolute position embeddings (sinusoidal or learned), Shaw-type and T5-type relative biases, and ALiBi.
For example, ALiBi is very attractive in its design philosophy of "training on short sequences and applying it to long sequences at inference time (Train Short, Test Long)." However, it is not appropriate to directly compare these methods with YaRN. This is because you cannot simply swap in ALiBi or a T5-type bias as an "after-the-fact patch" onto a model that has already finished training optimized for RoPE's geometric structure. These should be considered as options only at new-design time.
7.4 Conditions under which YaRN should be adopted
Taking these into account, the conditions for a project where YaRN should be adopted become clear. Specifically, YaRN is most suitable when the following four requirements are met.
- The base LLM already adopts RoPE.
- You do not want to make major changes to the model architecture itself.
- You want to handle it with relatively low-cost continued training (fine-tuning) rather than full-scratch retraining.
- You want to maintain compatibility with existing inference/serving environments such as FlashAttention.
In other words, rather than a technology that pursues the academic generality of "what is the ideal position representation," YaRN is a very practical solution that directly answers the on-the-ground need to "quickly extend the context of an existing RoPE-based LLM at a realistic cost."
7.5 Caveats and limitations
Of course, YaRN is not a panacea that solves every problem, and there are some limitations to be aware of.
- No matter how much you refine the design, you cannot completely reduce the performance drop (degradation) in the original short context to zero.
- If you adopt Dynamic Scaling, which varies the factor according to context length, the implementation conditions on the inference-system side, such as KV cache management, become stricter.
- Naturally, it cannot be applied to models using position representations other than RoPE.
- A language model's ability to handle long contexts is not determined by position representation alone; depending on the distribution of training data and the characteristics of the task, a different fundamental approach may be needed.
It is best to use YaRN as a conditionally powerful tool for "using RoPE models longer while breaking their existing assets as little as possible."
8. Conclusion
YaRN is a groundbreaking method that reframes the context-length extension of RoPE-based LLMs not as a mere "extension of position data" but from the viewpoints of "role division across frequency bands" and "re-tuning of the attention distribution." Specifically, it firmly interpolates the low-frequency bands to avoid unknown data (OOD) outside the training range, while for the high-frequency bands it tries to leave the original structure as intact as possible to preserve local ordering information. On top of that, by globally correcting the shift in the attention logits caused by these changes, it greatly improves the efficiency of additional training and achieves stable performance even when the context length is substantially extended [1].
Seen this way, the true value of YaRN is not "simply being able to read longer." It lies in the point that "you can extend, with minimal touch-ups, the phase geometry (the structure the model assumes) that the attention heads already trained with RoPE depend on." Therefore, when you want to extend the context at a realistic cost while leveraging the strengths of an existing RoPE model, YaRN becomes a very strong option.
On the other hand, for new pre-training where you can choose the position representation from scratch, or for cases where you want to optimize length handling itself with an entirely different approach, we recommend not fixating on YaRN but broadly considering the overall design, including other methods.
9. References
In writing this article, we referred to the following works.
- Bowen Peng, Jeffrey Quesnelle, Honglu Fan, Enrico Shippole, et al. YaRN: Efficient Context Window Extension of Large Language Models. arXiv:2309.00071
- Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen. RoFormer: Enhanced Transformer with Rotary Position Embedding. arXiv:2104.09864
- Shouyuan Chen, Sherman Wong, Liangjian Chen, Yuandong Tian. Extending Context Window of Large Language Models via Position Interpolation. arXiv:2306.15595
- Ofir Press, Noah A. Smith, Mike Lewis. Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation. arXiv:2108.12409
- Yutao Sun, Li Dong, Barun Patra, et al. A Length-Extrapolatable Transformer. arXiv:2212.10554
- Ashish Vaswani, Noam Shazeer, Niki Parmar, et al. Attention Is All You Need. arXiv:1706.03762
- Peter Shaw, Jakob Uszkoreit, Ashish Vaswani. Self-Attention with Relative Position Representations. arXiv:1803.02155
- Colin Raffel, Noam Shazeer, Adam Roberts, et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. arXiv:1910.10683
- Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, Siva Reddy. The Impact of Positional Encoding on Length Generalization in Transformers. arXiv:2305.19466
Last Modified: April 5, 2026